# Kubernetes集群维护
# Etcd数据库备份与恢复
Kubernetes 使用 Etcd 数据库实时存储集群中的数据,安全起见,一定要备份!
# kubeadm部署方式
# 环境准备
- 安装etcd工具
$ yum install etcd
- 备份
# 指定ectd的api版本号为3
$ ETCDCTL_API=3 etcdctl \
# 使用快照保存模式,并保存到文件snap.db
snapshot save snap.db \
# etcd的地址
--endpoints=https://127.0.0.1:2379 \
# ca证书
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
# server证书
--cert=/etc/kubernetes/pki/etcd/server.crt \
# server的key
--key=/etc/kubernetes/pki/etcd/server.key
- 测试
# 删除控制器web
$ kubectl delete deploy web
- 恢复
- 先暂停kube-apiserver和etcd容器
$ mv /etc/kubernetes/manifests /etc/kubernetes/manifests.bak
$ mv /var/lib/etcd/ /var/lib/etcd.bak
# 文件夹移除之后,kubectl就无法访问集群了
$ kubectl get pod
The connection to the server 10.69.1.160:6443 was refused - did you specify the right host or port?
- 恢复
$ ETCDCTL_API=3 etcdctl snapshot restore snap.db --data-dir=/var/lib/etcd
2021-06-07 22:08:09.402812 I | mvcc: restore compact to 3416081
2021-06-07 22:08:09.424201 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
- 启动kube-apiserver和etcd容器
$ mv /etc/kubernetes/manifests.bak /etc/kubernetes/manifests
# 可以发现刚才删掉的web已经恢复了,这就完成了备份与恢复
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
web 1/1 1 1 25h
# 二进制部署方式
- 备份
# 指定etcd的api版本号为3
$ ETCDCTL_API=3 etcdctl \
# 使用快照保存模式,保存到文件snap.db
snapshot save snap.db \
# 对一个节点的ectd进行备份
--endpoints=https://10.69.1.160:2379 \
# 相关证书地址,具体的地址需要看搭建k8s集群的时候怎么设置的
--cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem \
--key=/opt/etcd/ssl/server-key.pem
- 恢复
- 先暂停kube-apiserver和etcd
# 停止kube apiserver
$ systemctl stop kube-apiserver
# 停止etcd
$ systemctl stop etcd
# 备份etcd配置文件
$ mv /var/lib/etcd/default.etcd /var/lib/etcd/default.etcd.bak
- 在每个节点上恢复
# 指定etcd版本号位3,通过镜像恢复的模式从文件snap.db恢复
$ ETCDCTL_API=3 etcdctl snapshot restore snap.db \
# 当前节点名称
--name etcd-1 \
# 当前节点的ip地址需要和当前节点名称一致
# 有几个节点,就写几个etcd-n=https://xxx.xxx.xxx.xx:2380,逗号分隔,2380是etcd集群通信的端口
--initial-cluster="etcd-1=https://10.69.1.160:2380,etcd-2=https://10.69.1.161:2380" \
--initial-cluster-token=etcd-cluster \
# 当前节点的ip地址
--initial-advertise-peer-urls=https://10.69.1.160:2380 \
# ectd配置文件恢复
--data-dir=/var/lib/etcd/default.etcd
- 启动kube-apiserver和etcd
$ systemctl start kube-apiserver
$ systemctl start etcd
# kubeadm对K8s集群进行版本升级
Kubernetes每隔3个月发布一个小版本
# 升级策略
始终保持最新
一般不太现实,很难去推行。
每半年升级一次,这样会落后社区1~2个小版本
一年升级一次,或者更长,落后版本太多
一般比较合适,如果不太追求k8s的特性,追求比较稳定的环境,保持这种升级速度就ok了,官方也比较建议这种方式。
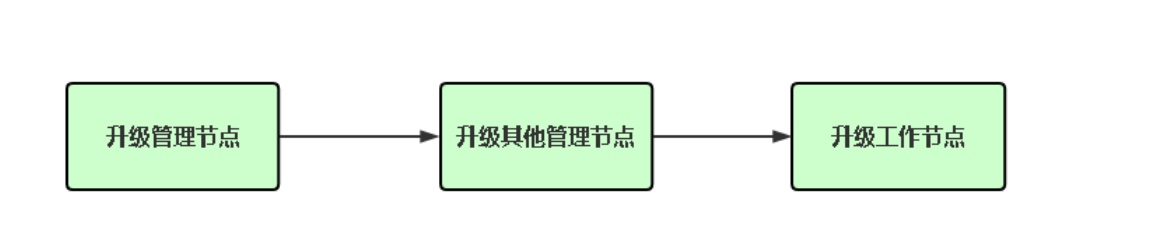
# 升级基本流程
# 注意事项
- 升级前必须备份所有组件及数据,例如etcd
- 千万不要跨多个小版本进行升级,例如从1.16升级到1.19
# 升级管理节点
# 查询集群版本
$ kubectl get node
NAME STATUS ROLES AGE VERSION
liuxiaolu-master Ready control-plane,master 28d v1.21.0
liuxiaolu-node Ready <none> 28d v1.21.0
# 1、查找最新版本号,可以看到比较适合的是1.21.1-0这个版本
$ yum list --showduplicates kubeadm --disableexcludes=kubernetes
Available Packages
...
kubeadm.x86_64 1.21.0-0 kubernetes
kubeadm.x86_64 1.21.1-0 kubernetes
# 2、升级kubeadm
$ yum install -y kubeadm-1.21.1-0 --disableexcludes=kubernetes
# 3、驱逐node上的pod,且不可调度, 如果有报错,加上对应的参数即可
$ kubectl drain liuxiaolu-master --ignore-daemonsets
node/liuxiaolu-master cordoned
error: unable to drain node "liuxiaolu-master", aborting command...
There are pending nodes to be drained:
liuxiaolu-master
error: cannot delete Pods with local storage (use --delete-emptydir-data to override): kubernetes-dashboard/dashboard-metrics-scraper-5594697f48-m65l9, kubernetes-dashboard/kubernetes-dashboard-5c785c8bcf-c4czw
# 比如遇到这个错,将驱逐命令改为kubectl drain liuxiaolu-master --ignore-daemonsets --delete-emptydir-data即可
# 4、检查集群是否可以升级,并获取可以升级的版本
$ kubeadm upgrade plan
# 5、执行升级, 看见下面的提示就算是升级成功了
$ kubeadm upgrade apply v1.21.1
...
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.21.1". Enjoy!
...
# 6、取消不可调度
$ kubectl uncordon liuxiaolu-master
# 7、升级kubelet和kubectl。如果不升级的话,使用命令kubectl get node查询,会看到还是1.21.0这个版本
$ yum install -y kubelet-1.21.1-0 kubectl-1.21.1-0 --disableexcludes=kubernetes
# 8、重启kubelet
$ systemctl daemon-reload
$ systemctl restart kubelet
# 重启完成之后查看node,就可以看到已经升级成功了
$ kubectl get node
NAME STATUS ROLES AGE VERSION
liuxiaolu-master Ready control-plane,master 28d v1.21.1
liuxiaolu-node Ready <none> 28d v1.21.0
# 升级工作节点
# 1、升级kubeadm
$ yum install -y kubeadm-1.21.1-0 --disableexcludes=kubernetes
# 2、驱逐node上的pod,且不可调度【推荐在master节点执行】
$ kubectl drain liuxiaolu-node --ignore-daemonsets
# 3、升级kubelet配置
$ kubeadm upgrade node
# 4、升级kubelet和kubectl
$ yum install -y kubelet-1.21.1-0 kubectl-1.21.1-0 --disableexcludes=kubernetes
# 5、重启kubelet
$ systemctl daemon-reload
$ systemctl restart kubelet
# 6、取消不可调度,节点重新上线【推荐在master节点执行】
$ kubectl uncordon liuxiaolu-node
# 再次查看发现已经升级成功
$ kubectl get node
NAME STATUS ROLES AGE VERSION
liuxiaolu-master Ready control-plane,master 28d v1.21.1
liuxiaolu-node Ready <none> 28d v1.21.1
# K8s集群节点正确下线流程
如果你想维护某个节点或者删除节点正确流程如下:
- 获取节点列表
$ kubectl get node
- 设置不可调度
$ kubectl cordon <node_name>
- 驱逐节点上的Pod
$ kubectl drain <node_name> --ignore-daemonsets
- 移除节点
$ kubectl delete node <node_name>
# 集群故障排查
# 应用部署
# describe
$ kubectl describe [type] [name]
# logs
# 括号内容为可选项,指定容器名称
$ kubectl logs [pod名称] (-c [containerName])
# exec -it
$ kubectl exec -it [podName] -- sh
# 组件不能正常工作
- 管理节点组件
- kube-apiserver
- kube-controller-manager
- kube-scheduler
-工作节点组件
- kubelet
- kube-proxy
# 需要先区分是二进制部署还是kubeadm部署的
kubeadm 除kubelet外,其他组件均采用静态pod启动
二进制 所有组件均采用systemd管理
常见问题
- 网络不通
- 启动失败,一般配置文件或者依赖服务
- 平台不兼容
# service访问异常
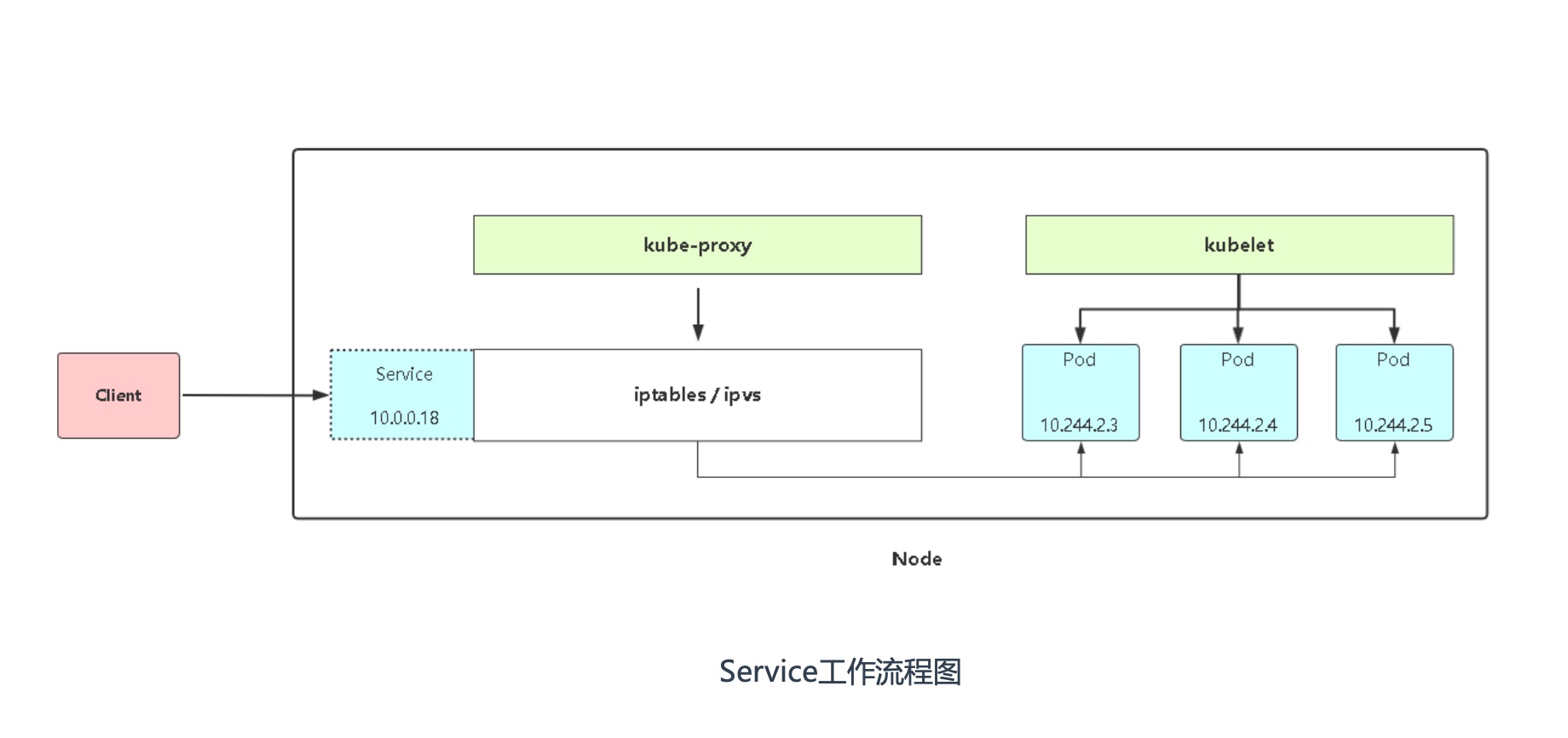
- Service是否关联Pod?
- Service指定target-port端口是否正常?
- Pod正常工作吗?
- Service是否通过DNS工作?
- kube-proxy正常工作吗?
- kube-proxy是否正常写iptables规则?
- cni网络插件是否正常工作?