# JVM调优工具以及常见问题分析思路
# 工具篇
# jmap
jmap -heap
<pid>查询堆内存各区域占用情况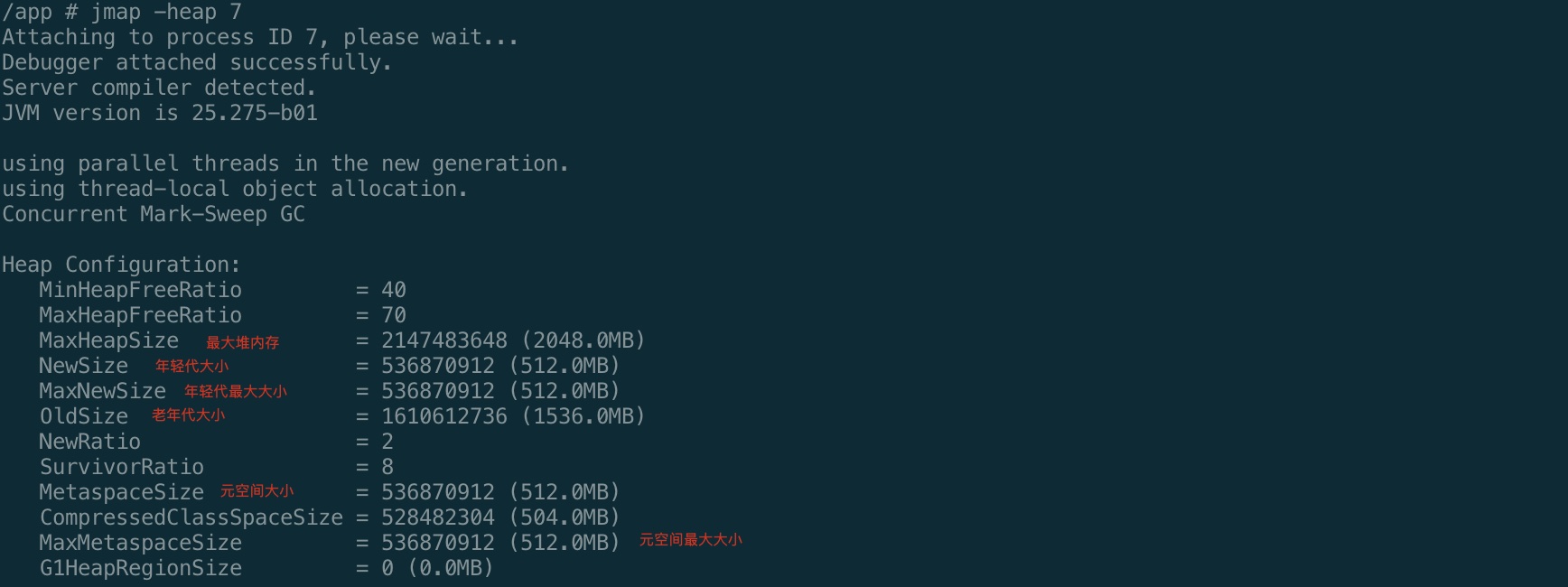
jmap -histo
<pid>: 查询历史生成的实例,可用来分析内存异常jmap -histo:live
<pid>: 查询当前生成的实例,执行过程中可能会触发一次full gc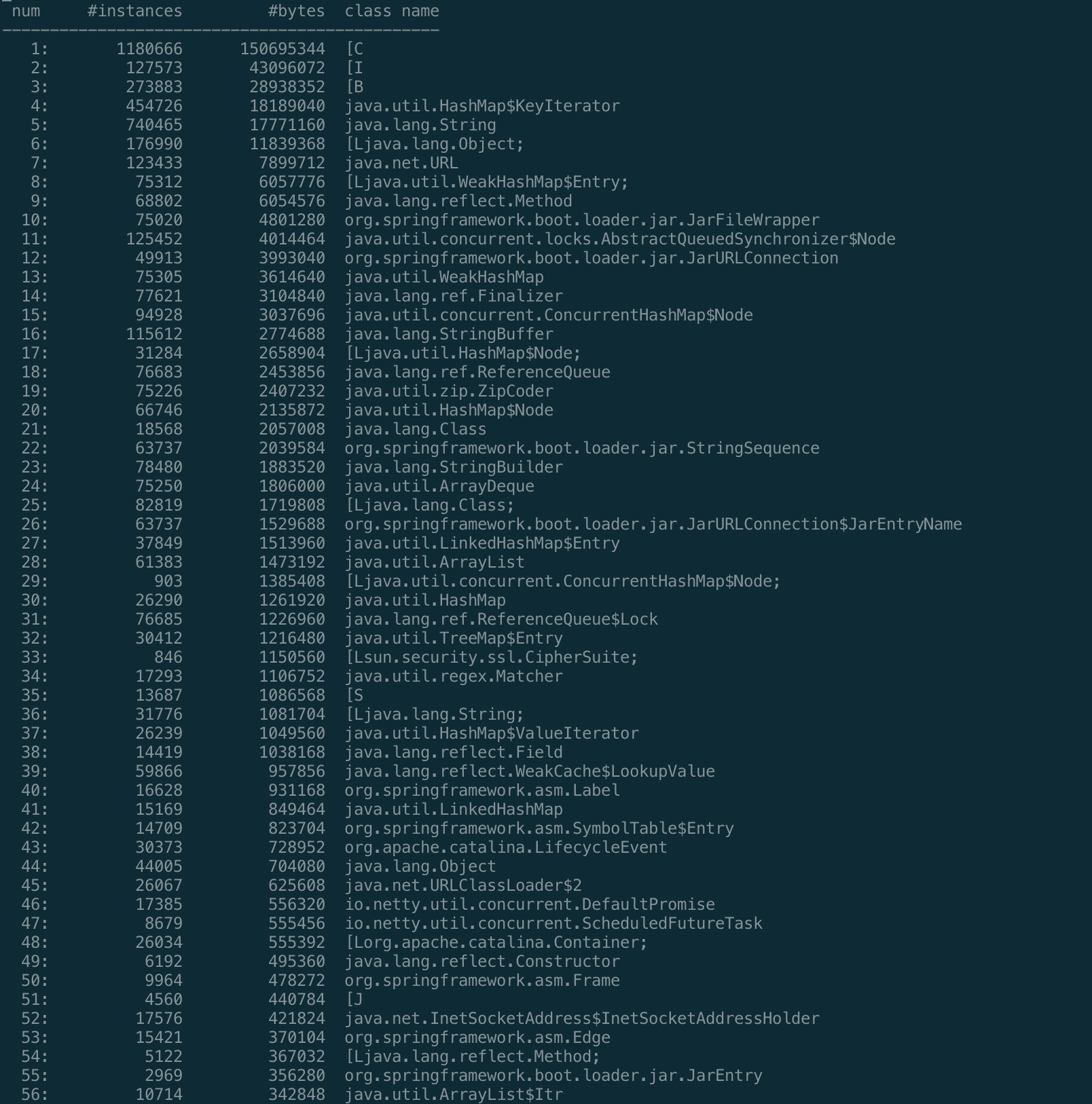
参数说明:
- num: 序号
- instances: 实例数量
- bytes: 占用内存大小
- class name: 类名称
- jmap -dump:format=b,file=
<dumpfilename>.hprof<pid>
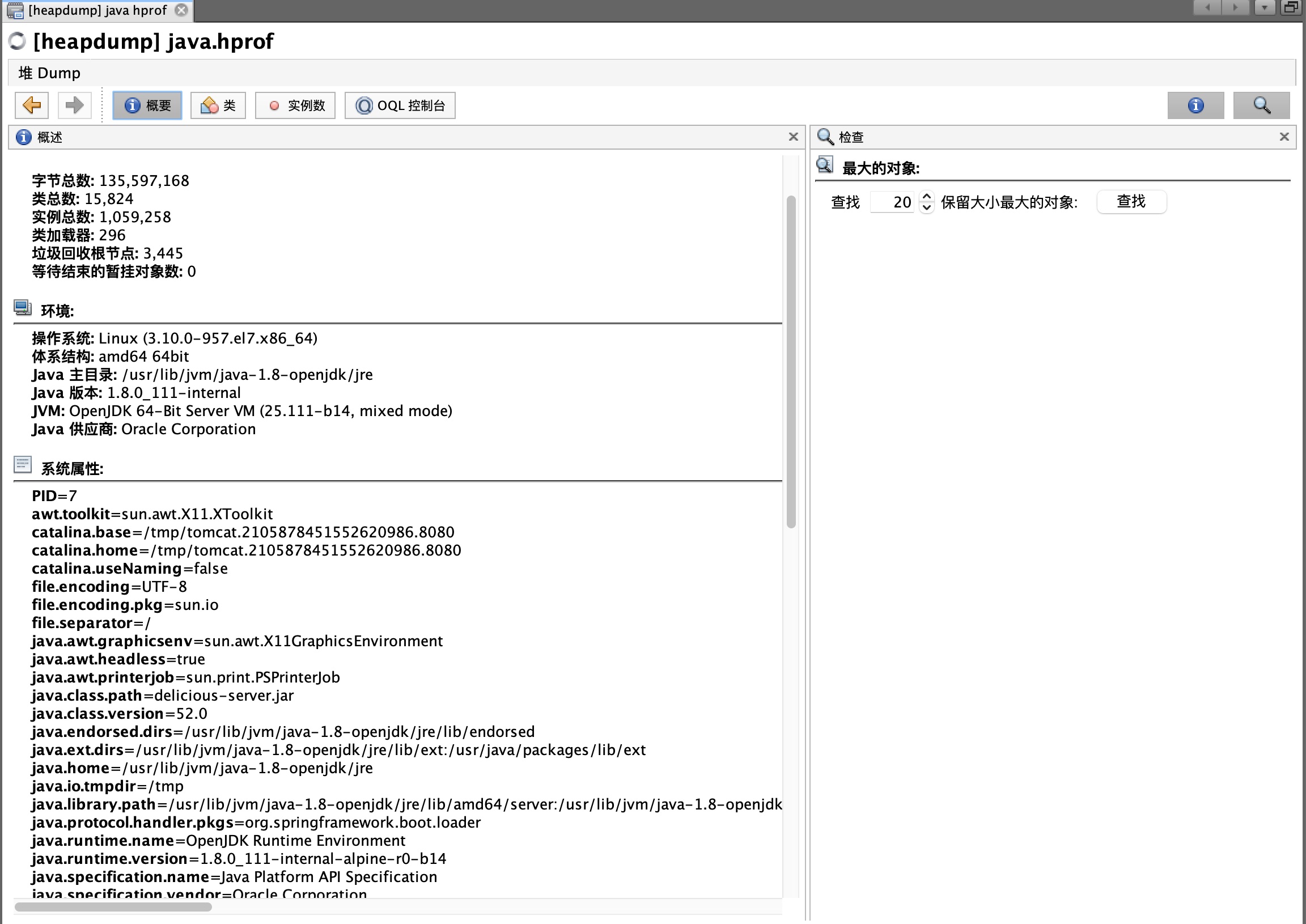
下载dump文件,可以将文件装入到jvisualvm中分析
# jvisualvm
在命令行输入jvisualvm,打开jvisualvm

装入
<dumpfilename>.hprof文件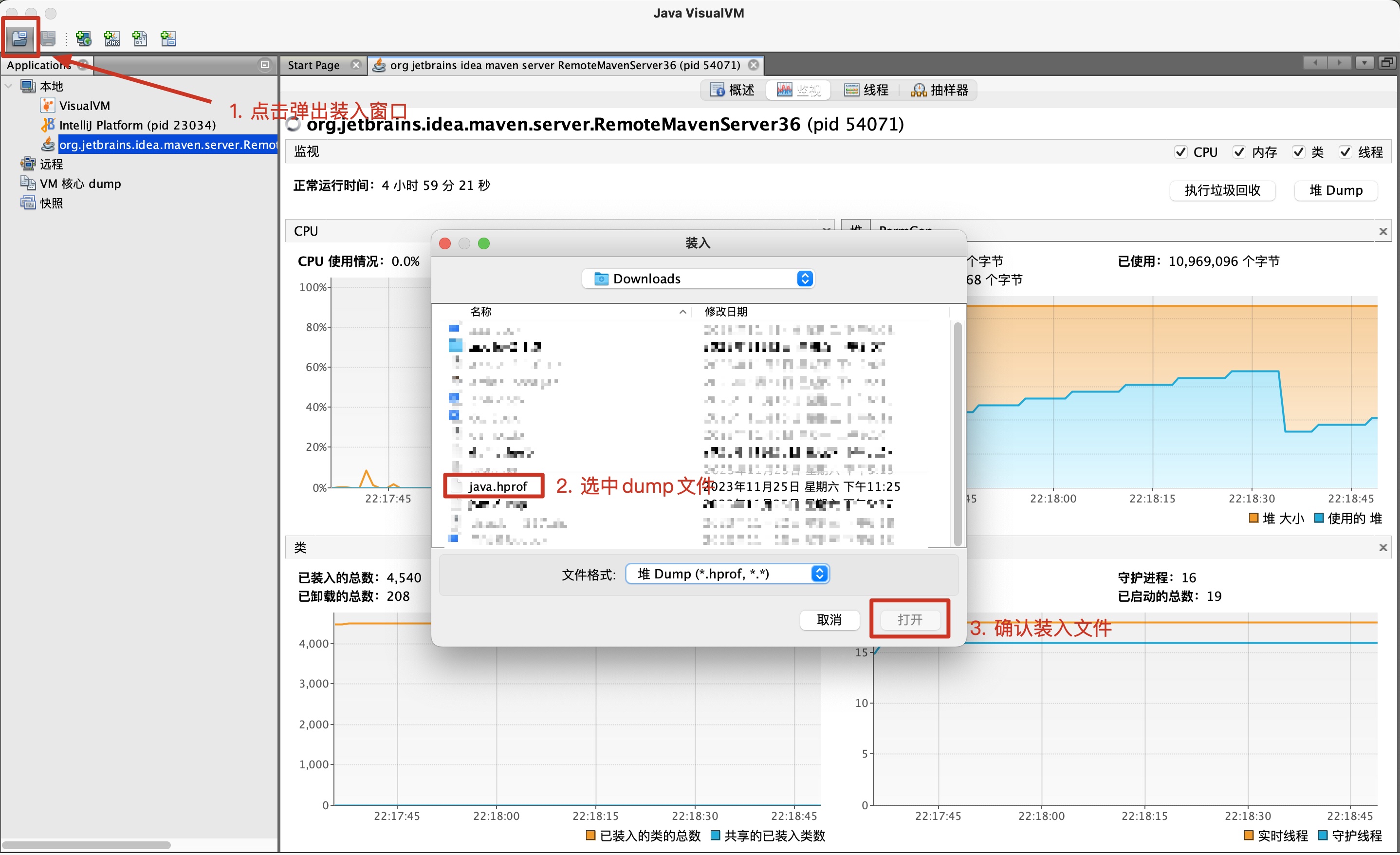
# jinfo
jinfo -flags
<pid>查询应用启动参数
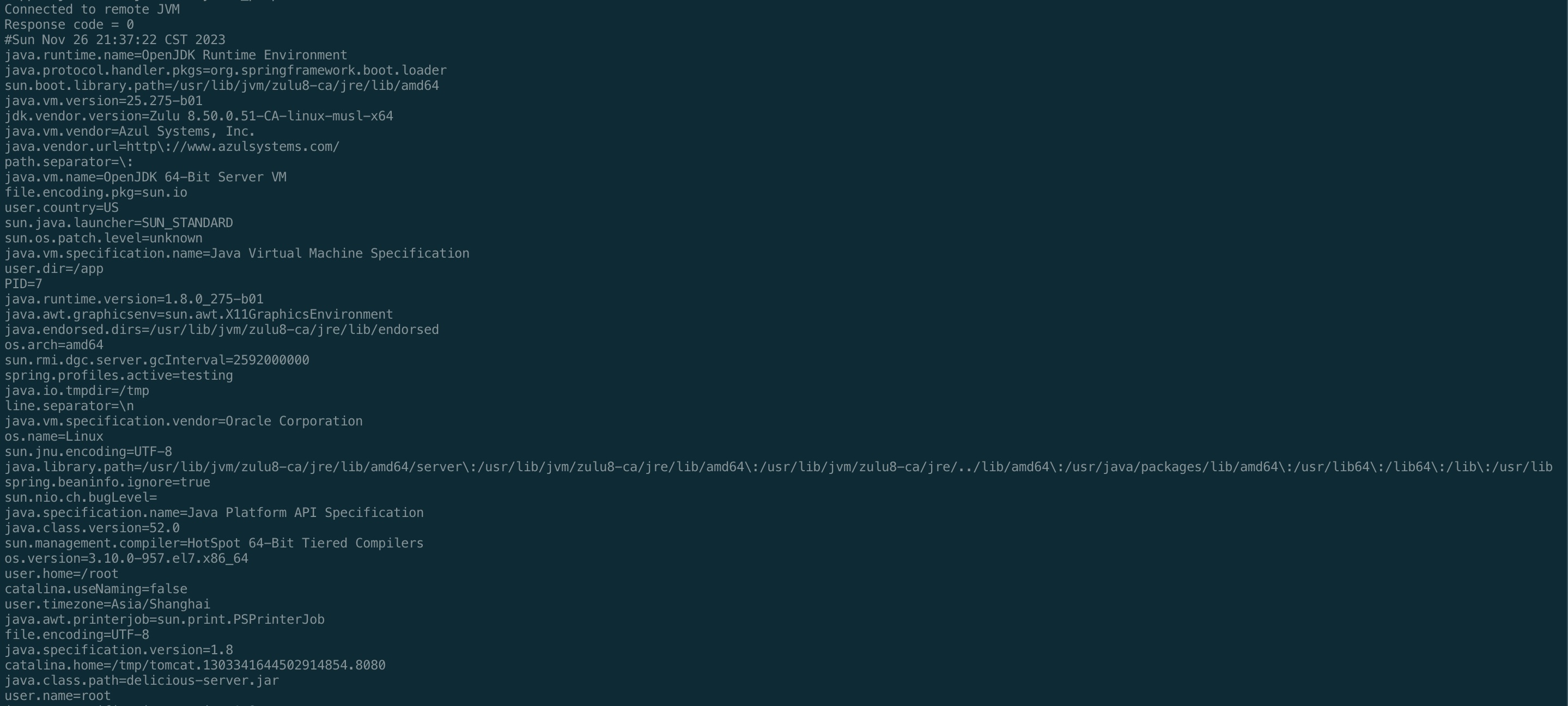
jinfo -sysprops
<pid>
jattach
<pid>jcmd VM.system_properties
查询java系统参数
# jstack
jstack
<pid>查找死锁找出占用cpu最高的线程堆栈信息
top -p
<pid>
按H查询线程详情
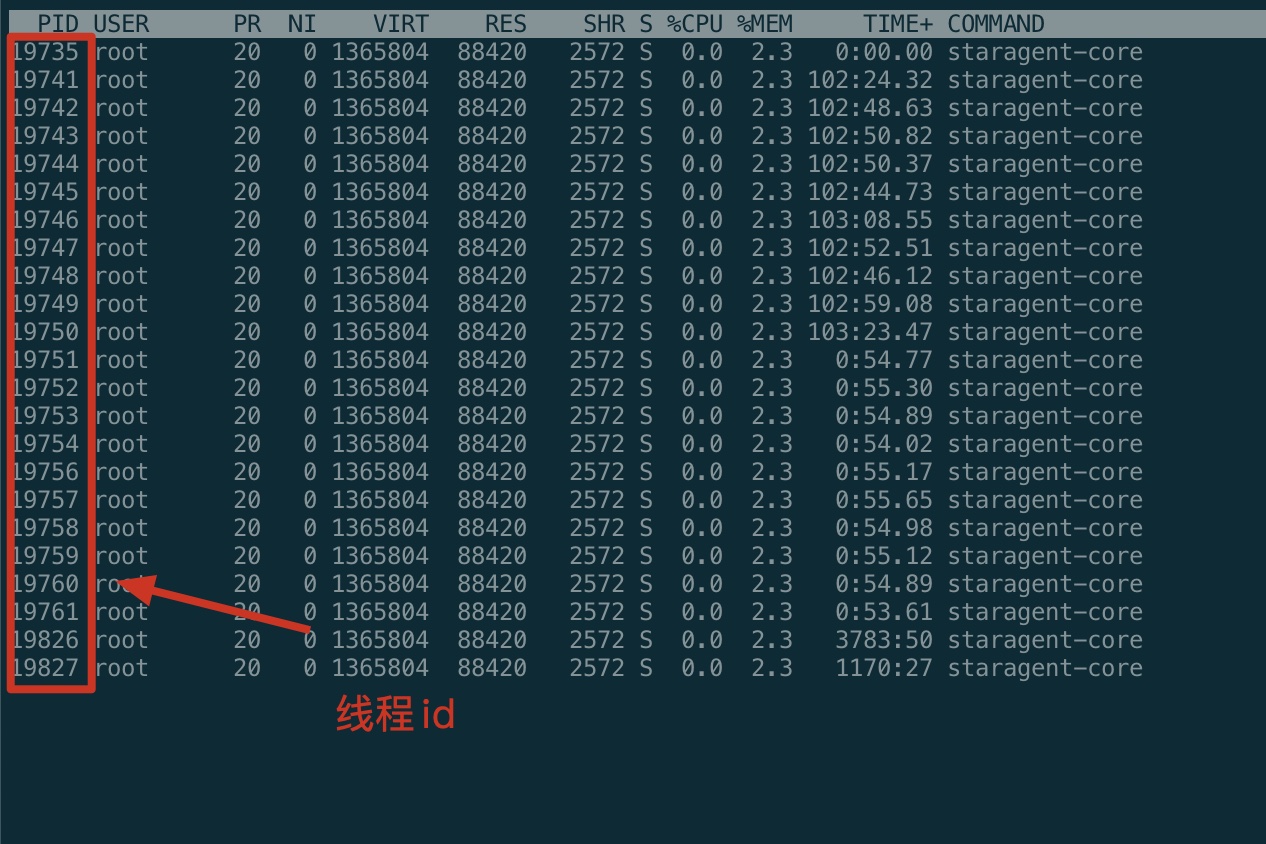
找到内存和cpu占用最高的线程tid,比如19735
转为十六进制得到 0x4d17,此为线程id的十六进制表示
在线转换进制:https://jisuan5.com/hexadecimal/
- 执行 jstack
<pid>|grep -A 10 4d17,得到线程堆栈信息中 4d17 这个线程所在行的后面10行,从堆栈中可以发现导致cpu飙高的调用方法 - 查看对应的堆栈信息找出可能存在问题的代码
# jstat
- jstat [-命令选项] [vmid] [间隔时间(毫秒)] [查询次数] 评估程序内存使用及GC压力整体情况
eg:每隔1s打印一次内存及gc情况,共打印10次

- S0C:第一个幸存区的大小,单位KB
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小(元空间)
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位s
- GCT:垃圾回收消耗总时间,单位s
# Arthas
Arthas 是 Alibaba 在 2018 年 9 月开源的 Java 诊断工具。支持 JDK6+, 采用命令行交互模式,可以方便的定位和诊断线上程序运行问题。
# 下载arthas
- github 下载
wget https://alibaba.github.io/arthas/arthas-boot.jar
- Gitee 下载
wget https://arthas.gitee.io/arthas-boot.jar
# 使用
用
java -jar arthas-boot.jar运行,可以识别机器上所有Java进程
输入进程号,回车进入,下图即为成功
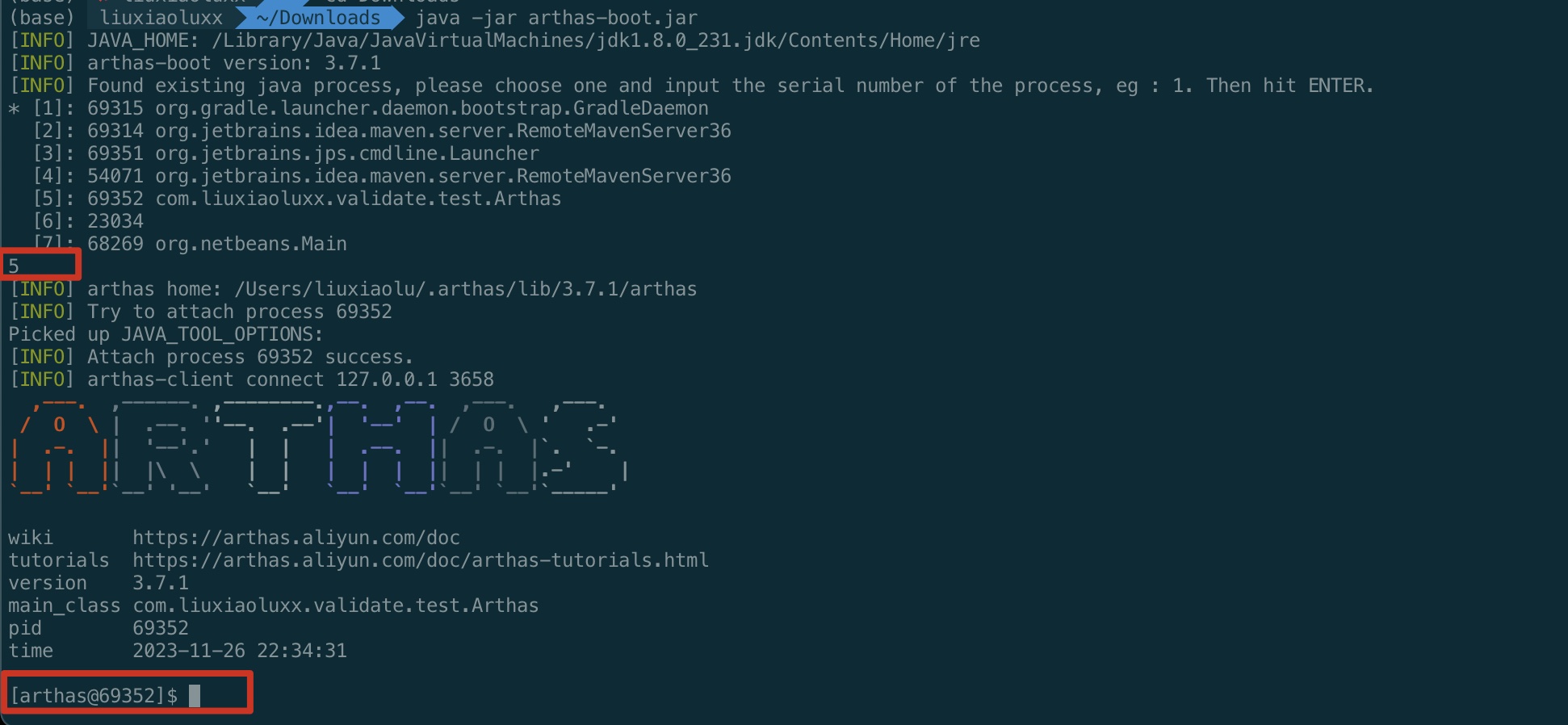
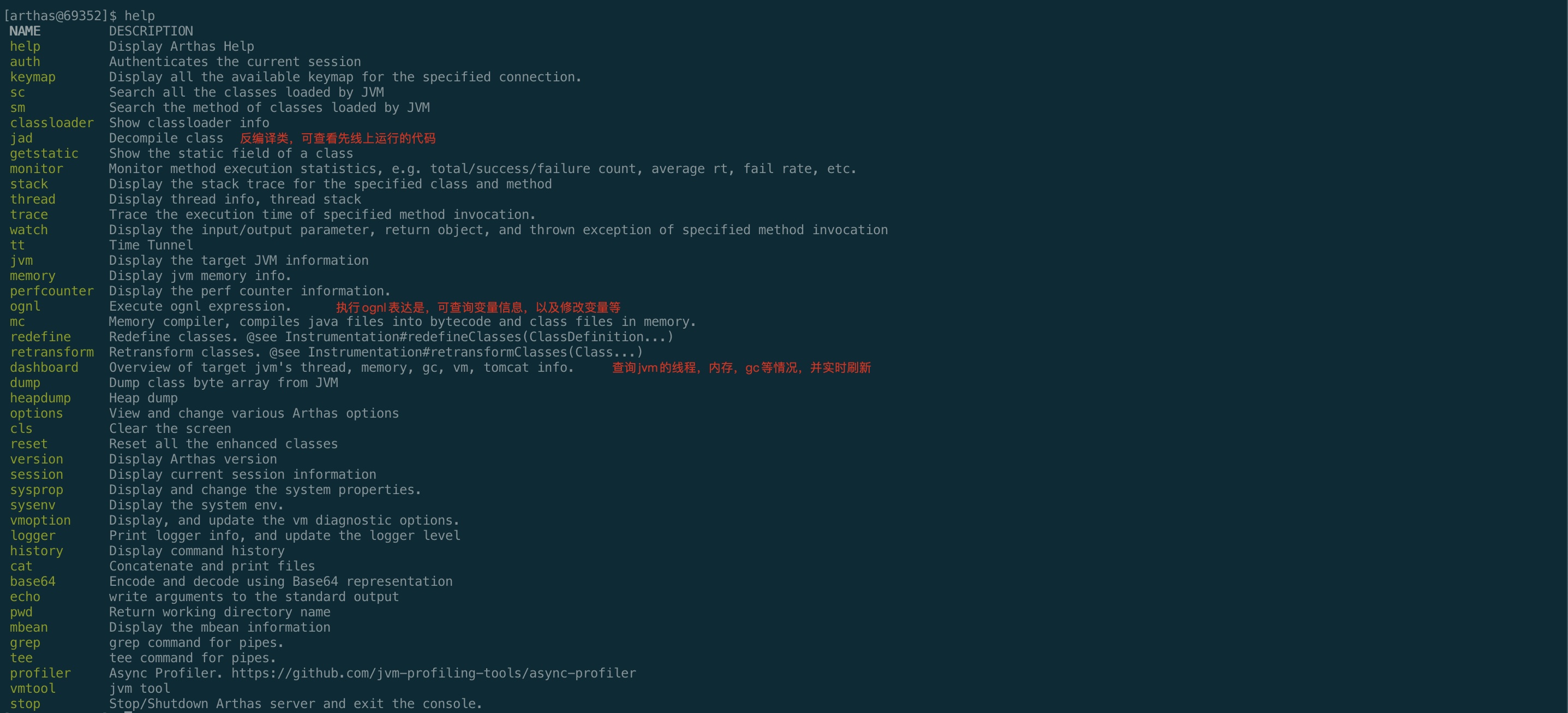
输入help查询所有支持的命令
# GC日志
# 日志详解
对于java应用我们可以通过一些配置把程序运行过程中的gc日志全部打印出来,然后分析gc日志得到关键性指标,分析GC原因,调优JVM参数。 打印GC日志方法,在JVM参数里增加参数,%t 代表时间
-Xloggc:./gc-%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCCause
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M
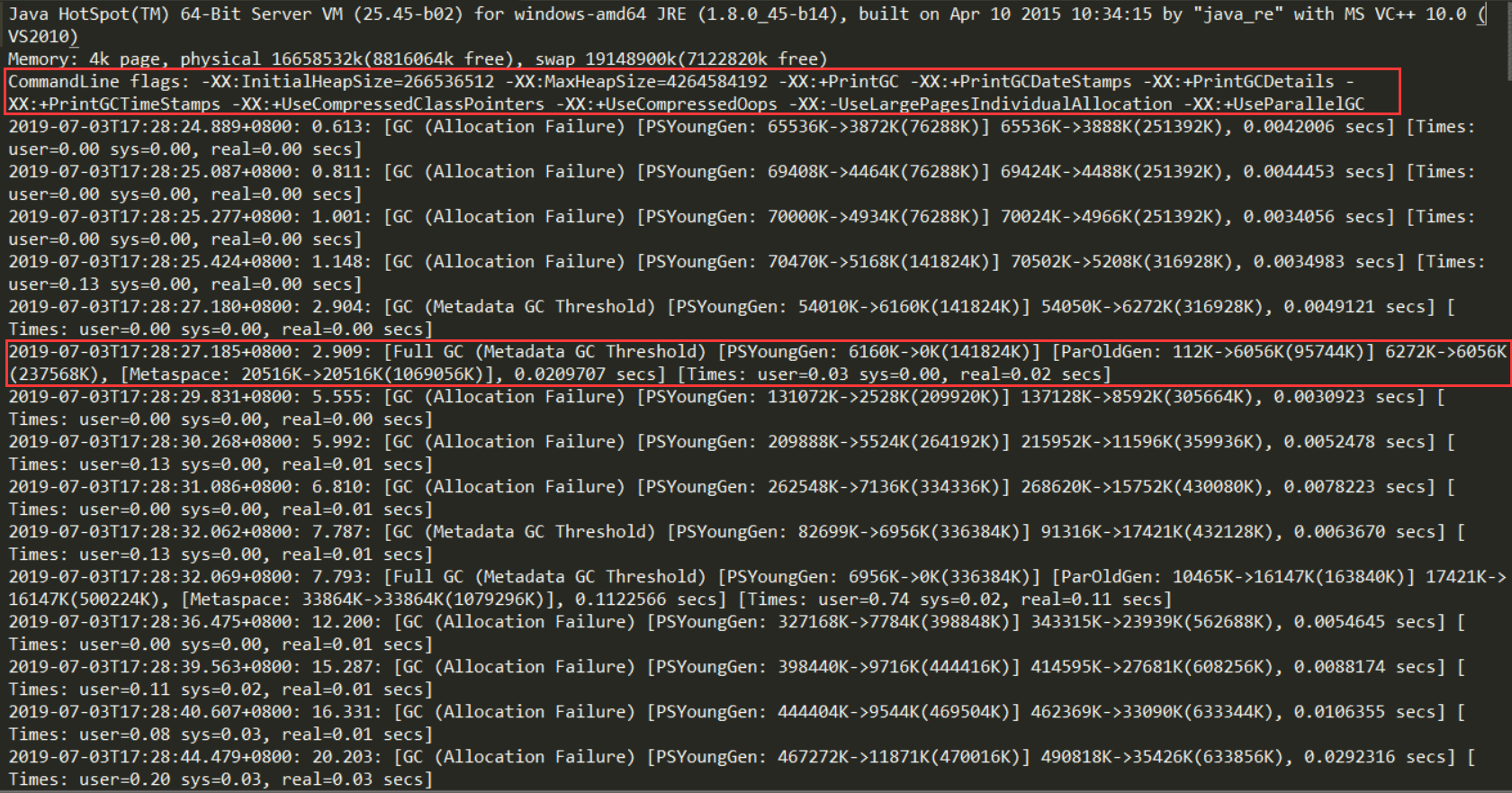 我们可以看到图中第一行红框,是项目的配置参数。这里不仅配置了打印GC日志,还有相关的VM内存参数。
第二行红框中的是在这个GC时间点发生GC之后相关GC情况。
我们可以看到图中第一行红框,是项目的配置参数。这里不仅配置了打印GC日志,还有相关的VM内存参数。
第二行红框中的是在这个GC时间点发生GC之后相关GC情况。
- 对于2.909: 这是从jvm启动开始计算到这次GC经过的时间,前面还有具体的发生时间日期。
- Full GC(Metadata GC Threshold)指这是一次full gc,括号里是gc的原因, PSYoungGen是年轻代的GC,ParOldGen是老年代的GC,Metaspace是元空间的GC
- 6160K->0K(141824K),这三个数字分别对应GC之前占用年轻代的大小,GC之后年轻代占用,以及整个年轻代的大小。
- 112K->6056K(95744K),这三个数字分别对应GC之前占用老年代的大小,GC之后老年代占用,以及整个老年代的大小。
- 6272K->6056K(237568K),这三个数字分别对应GC之前占用堆内存的大小,GC之后堆内存占用,以及整个堆内存的大小。
- 20516K->20516K(1069056K),这三个数字分别对应GC之前占用元空间内存的大小,GC之后元空间内存占用,以及整个元空间内存的大小。
- 0.0209707是该时间点GC总耗费时间。
# 图形化分析工具(gceasy)
dump gc日志
打开https://gceasy.io, 并进行登录
导入文件
等待分析结果
# 问题排查思路
# 程序死锁
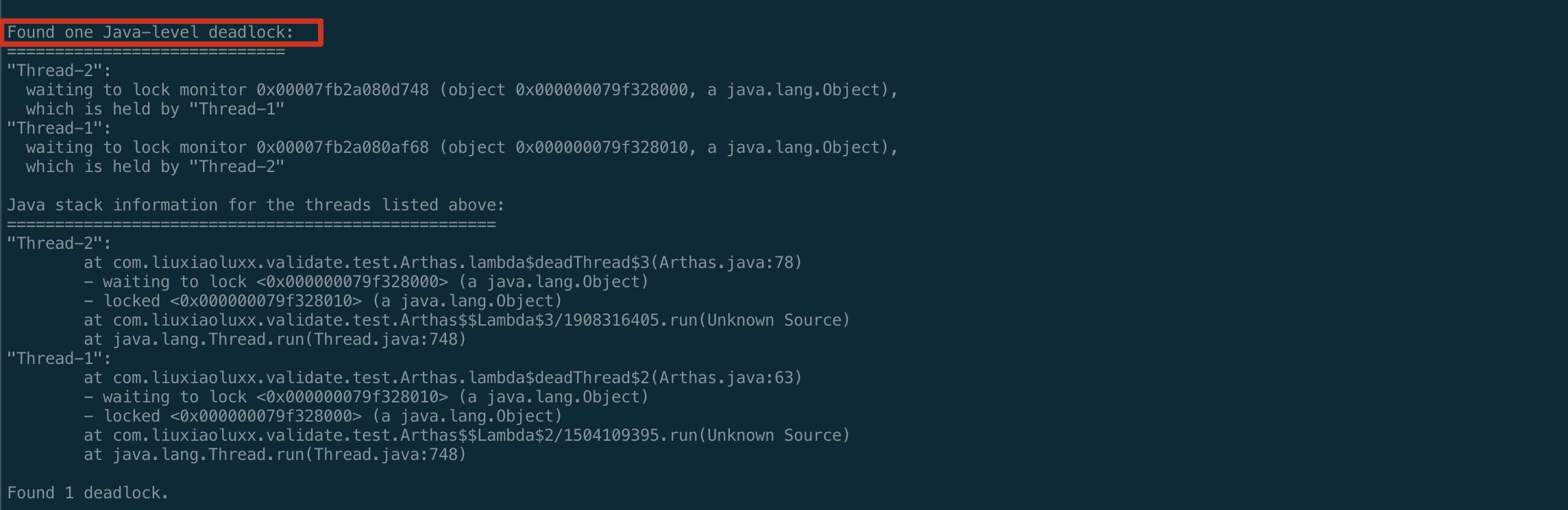
# 1. 用jstack <pid>查找死锁
eg: jstack 70445
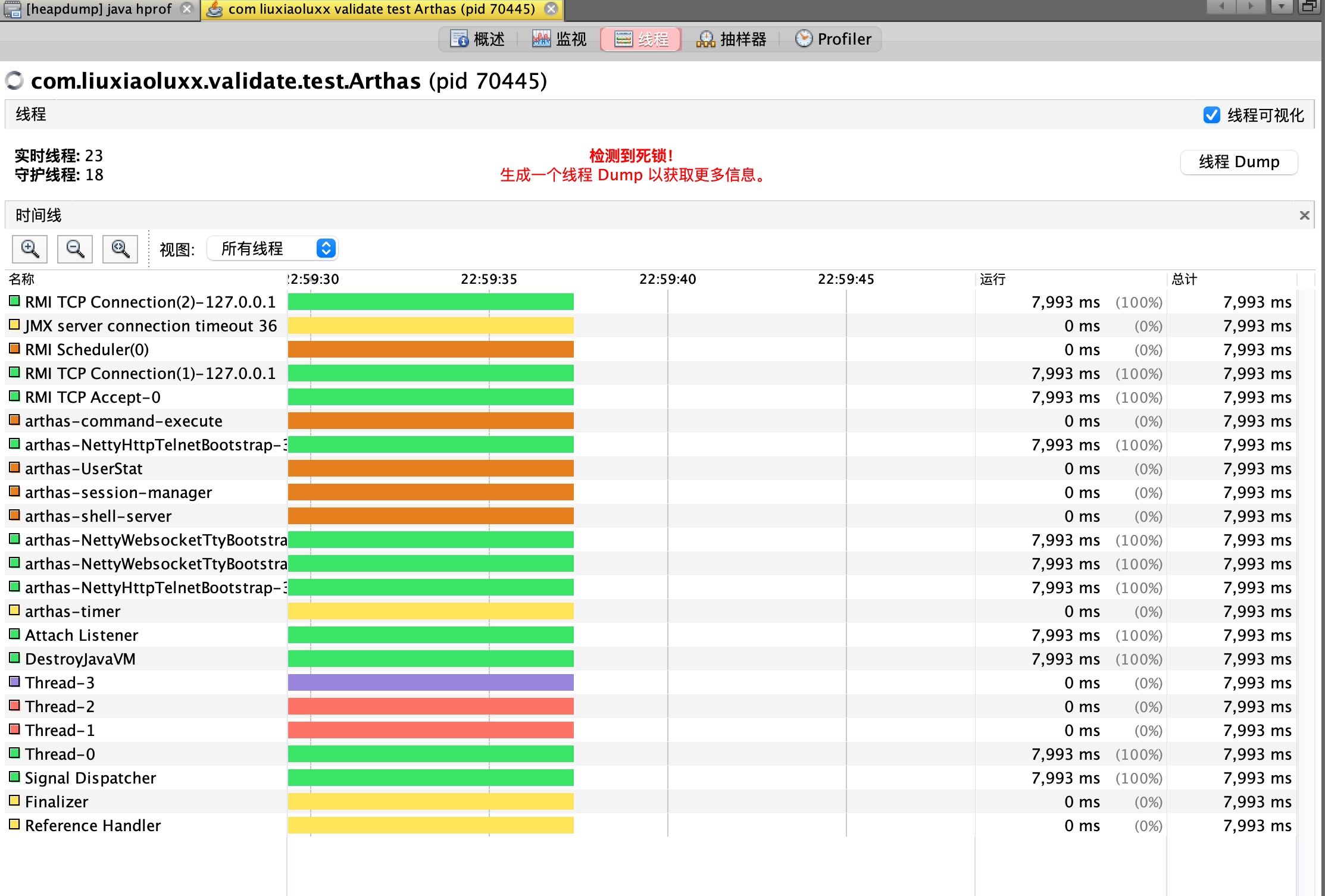
# 2. 用jvisualvm分析死锁(不推荐)
可以实时监测系统时,可使用该方法。但线上系统一般不会让你实时连接,所以不推荐使用该方法。
# 3. 用arthas的thread -b命令查询死锁

# CPU异常
# 1. 使用jstack查询
top -p
<pid>按H查询线程详情
找到内存和cpu占用最高的线程tid,比如19735
转为十六进制得到 0x4d17,此为线程id的十六进制表示
在线转换进制:https://jisuan5.com/hexadecimal/
- 执行 jstack
<pid>|grep -A 10 4d17,得到线程堆栈信息中 4d17 这个线程所在行的后面10行,从堆栈中可以发现导致cpu飙高的调用方法 - 查看对应的堆栈信息找出可能存在问题的代码
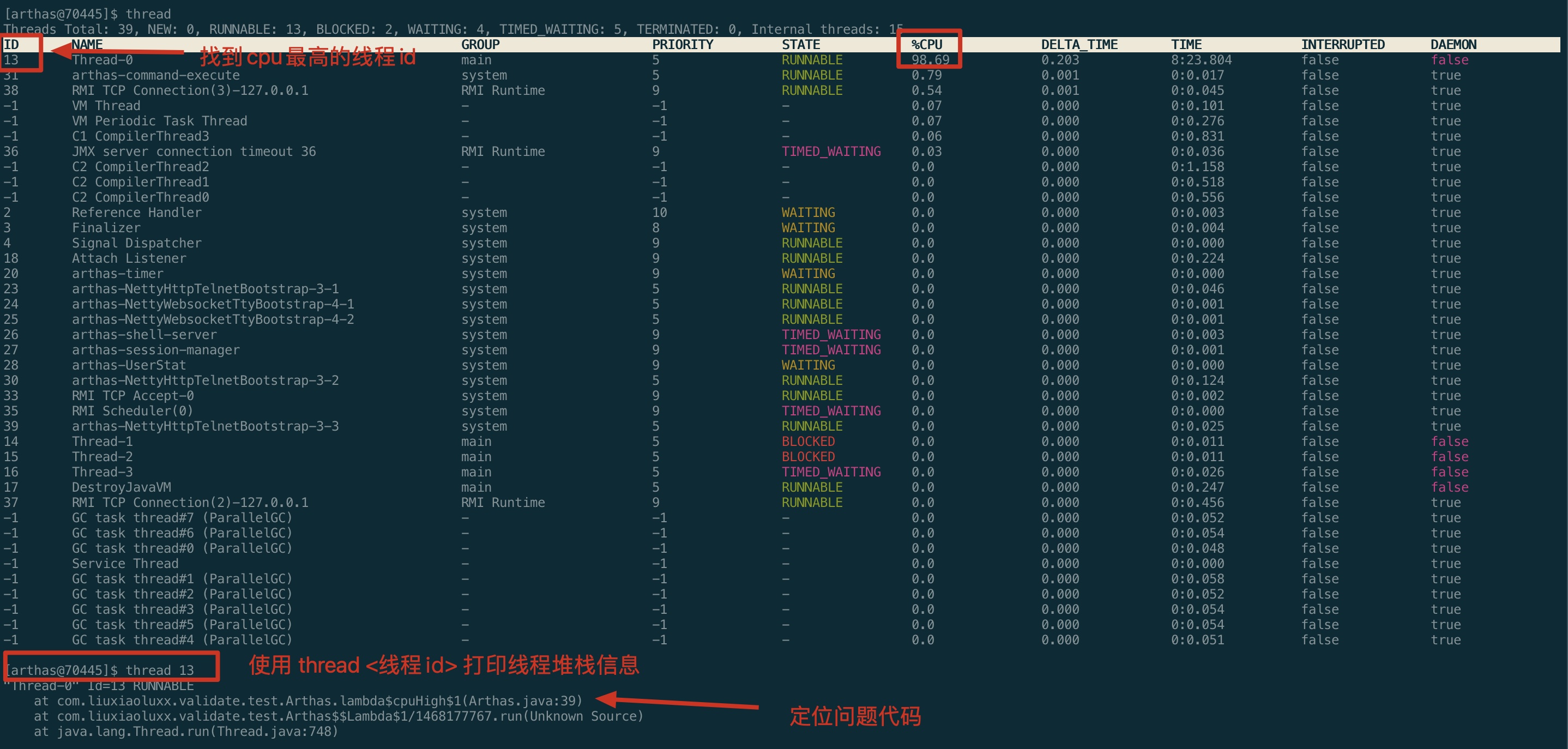
# 2. 使用arthas查询
- 使用thread命令找到消耗cpu最高的线程id
- 使用thread <线程id>命令查询线程堆栈
- 定位问题代码
# 内存异常
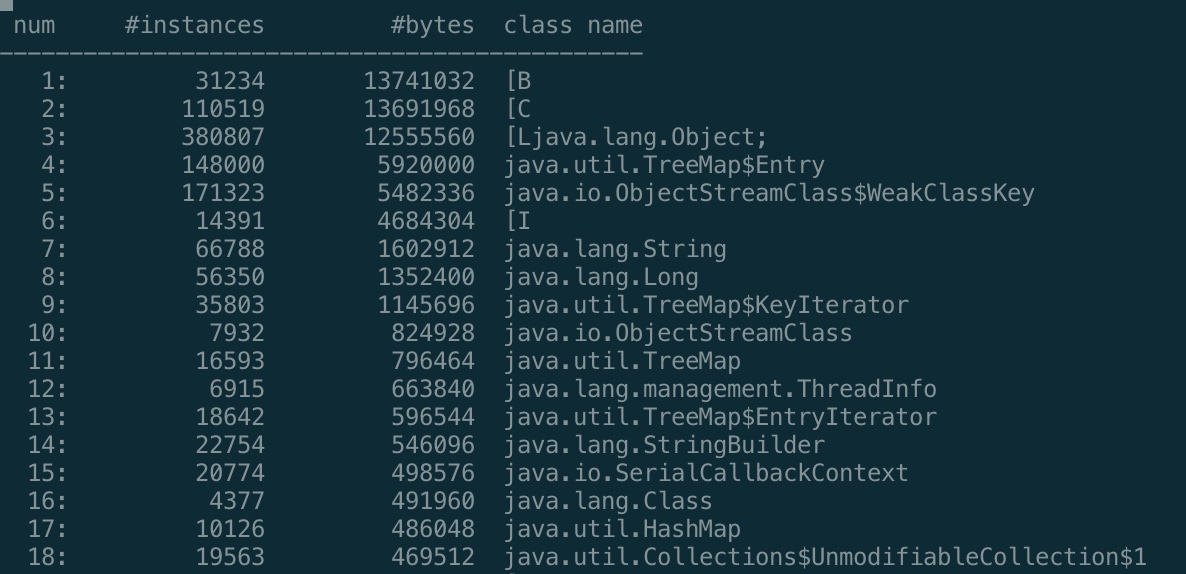
# 使用jmap -histo查询占用内存最高的实例
执行jmap -histo
<pid>> log.txt生成内存快照文件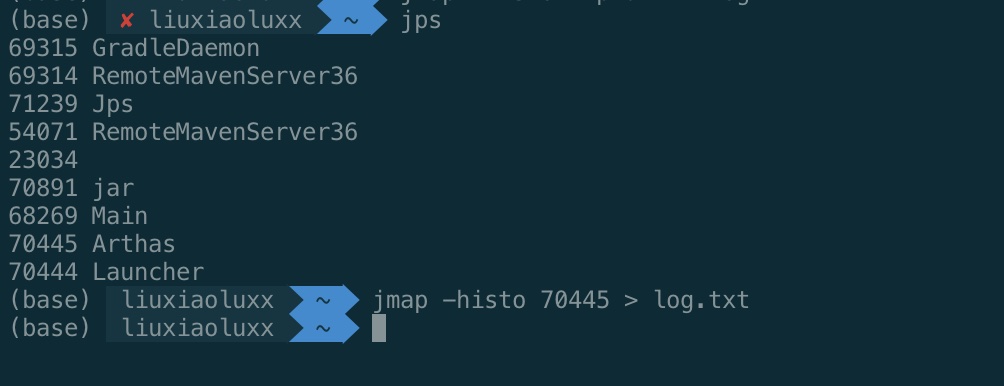
vi log.txt, 查询占用内存最高的实例(主要找与自己的工程相关的代码)
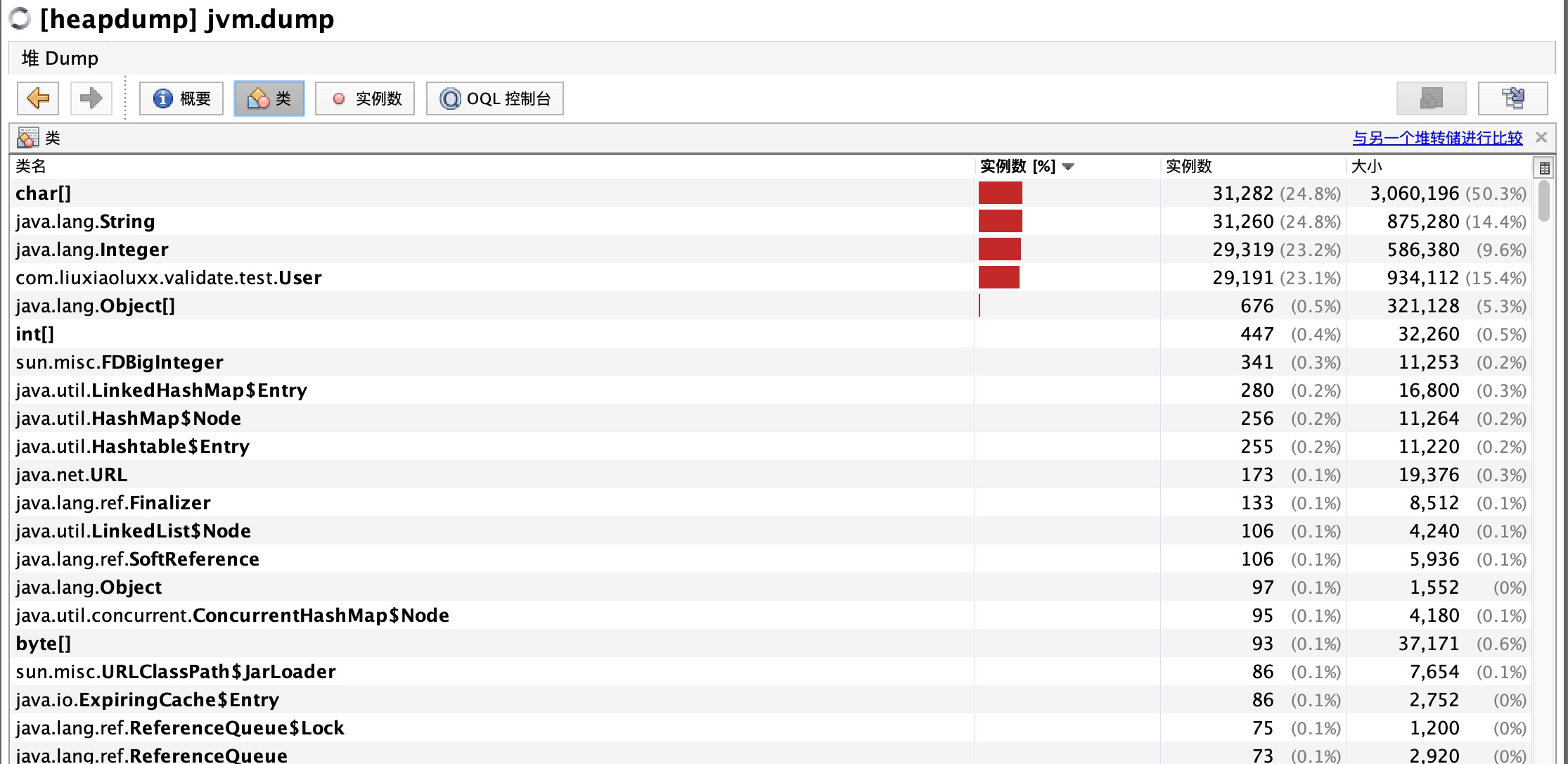
# 生成dump文件,下载后用jvisualvm分析
- jmap -dump:format=b,file=
<dumpfilename>.hprof<pid> - 在终端中输入jvisualvm打开jvisualvm
- 装入dump文件
- 分析类信息
# 使用arthas分析
- 使用heapdump命令生成dump文件
- 用jvisualvm分析
# FULL GC频繁
fullgc频繁一般有以下几个原因
- 元空间不够导致的多余full gc,这种情况可以适当增加元空间大小
- 显示调用System.gc()造成多余的full gc,这种一般线上尽量通过-XX:+DisableExplicitGC参数禁用,如果加上了这个JVM启动参数,那么代码中调用System.gc()没有任何效果
- 老年代空间分配担保机制
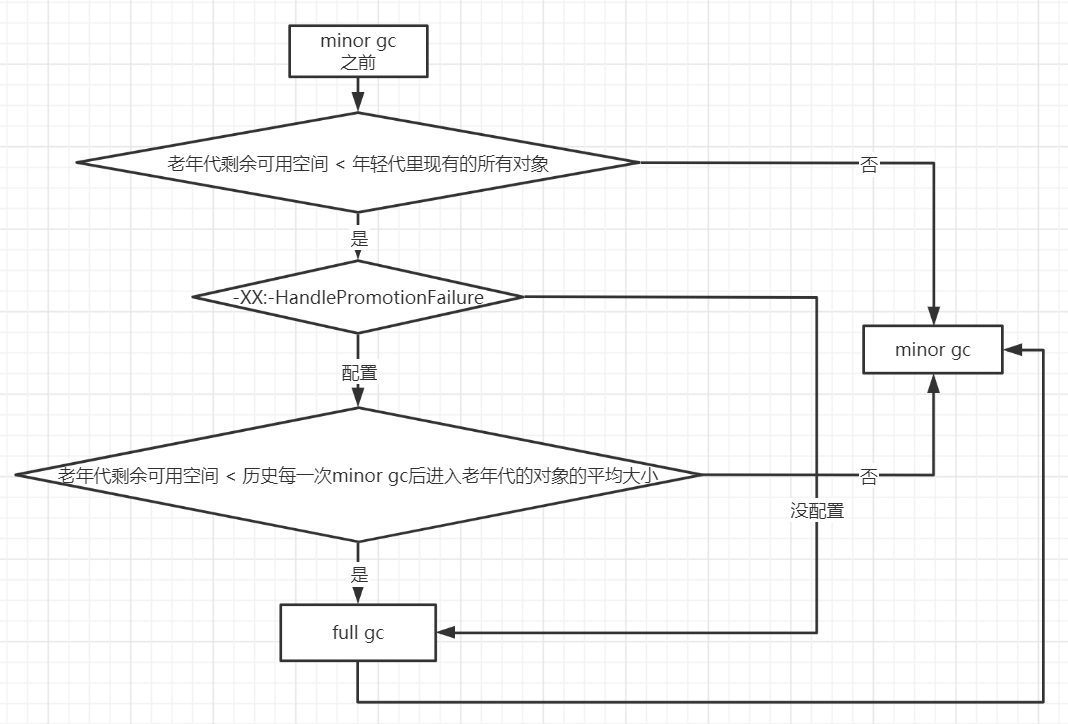
优化思路
- 尽量让朝生夕死的对象在ygc被回收掉,不要让这部分对象进入老年代。
- 可以适当调高年轻代的大小
- 增加对象动态年龄
- 分析gc日志,针对性优化
← 垃圾回收算法