# MySQL8之窗口函数
开窗函数也叫OLAP函数(Online Analytical Processing,联机分析处理),主要用来实时分析处理数据。MySQL之前的版本是不支持开窗函数的,从8.0版本之后开始支持开窗函数。
# 语法
func_name(<parameter>)
OVER([PARTITION BY <part_by_condition>]
[ORDER BY <order_by_list> ASC|DESC])
# 语法解析
函数分为两部分
一部分是函数名称,开窗函数的数量比较少,总共才11个开窗函数+聚合函数(所有的聚合函数都可以用作开窗函数)。根据函数的性质,有的需要写参数,有的不需要写参数。
另一部分为over语句,over()是必须要写的,里面的参数都是非必须参数,可以根据需求有选择地使用。
- 第一个参数是partition by + 字段,含义是根据此字段将数据集分为多份
- 第二个参数是order by + 字段,每个窗口的数据依据此字段进行升序或降序排列
开窗函数与分组聚合函数比较相似,都是通过指定字段将数据分成多份。
区别如下
- SQL 标准允许将所有聚合函数用作开窗函数,用OVER 关键字区分开窗函数和聚合函数。
- 聚合函数每组只返回一个值,开窗函数每组可返回多个值。
# 测试使用
- 创建一张表
CREATE TABLE `score` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`type` varchar(255) DEFAULT NULL COMMENT '学科',
`name` varchar(255) DEFAULT NULL COMMENT '姓名',
`score` double(10,2) DEFAULT NULL COMMENT '分数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
- 准备数据
INSERT INTO `score` (`type`, `name`, `score`) VALUES ('高等数学1', '张三', 100.00);
INSERT INTO `score` (`type`, `name`, `score`) VALUES ('高等数学1','李四', 100.00);
INSERT INTO `score` (`type`, `name`, `score`) VALUES ('高等数学1','王五', 87.00);
INSERT INTO `score` (`type`, `name`, `score`) VALUES ('高等数学1','张四', 85.00);
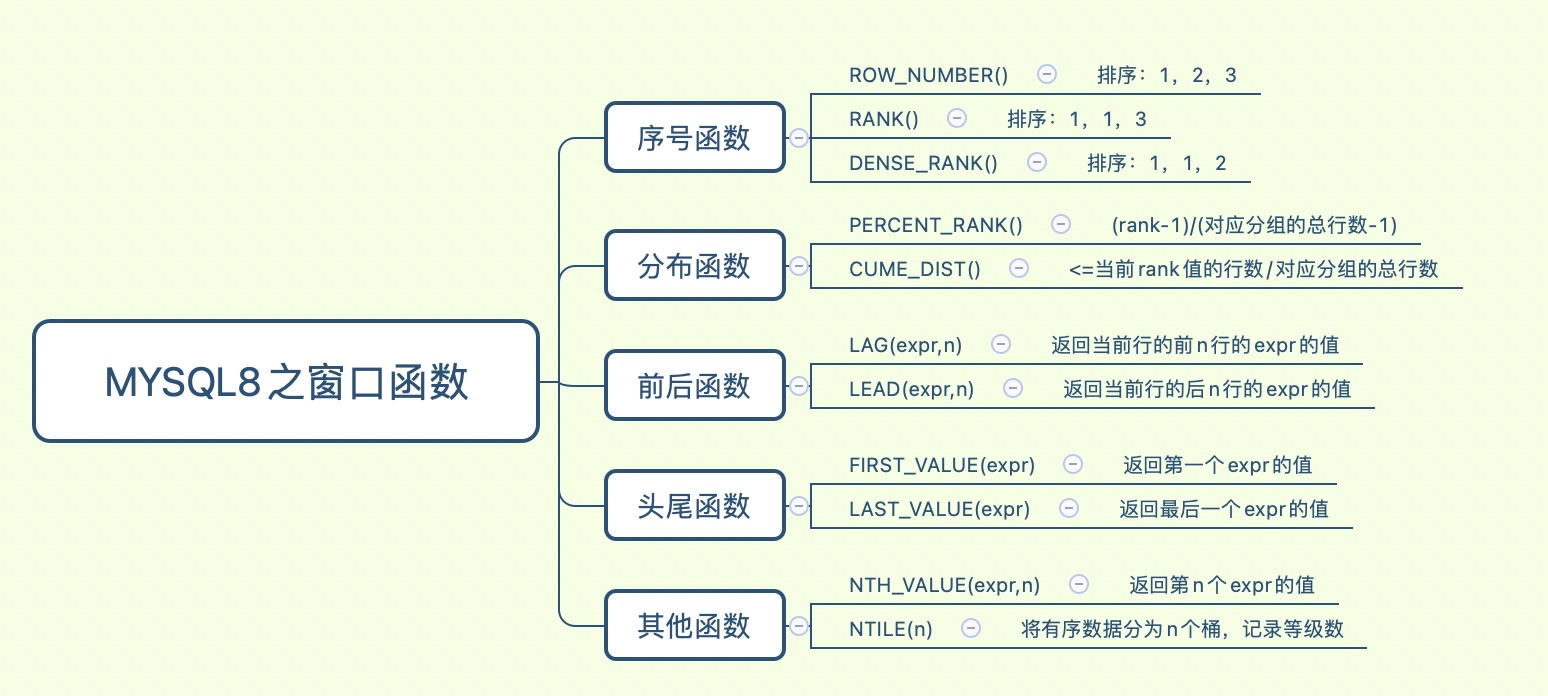
# 函数列表
# 序号函数
# 验证SQL
SELECT
*
FROM
(
SELECT
type,
name,
score,
ROW_NUMBER() OVER ( PARTITION BY type ORDER BY score desc) AS row_order,
RANK() OVER ( PARTITION BY type ORDER BY score desc) AS rank_order,
DENSE_RANK() OVER ( PARTITION BY type ORDER BY score desc) AS dense_order
FROM
score
) AS t;
# 验证结果
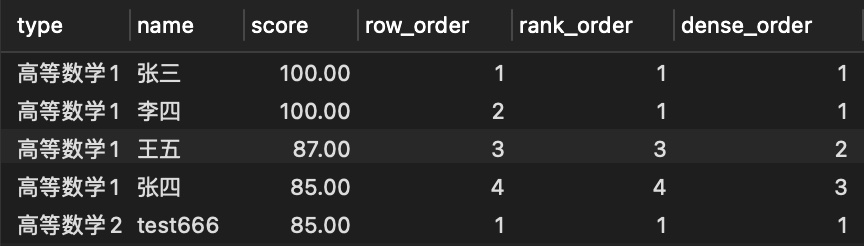
- 可以明显的看到,
ROW_NUMBER函数就是在分组后对数据进行自然排序 - 而
RANK函数和DENSE_RANK都是在计算排名,区别是出现并列之后,是否占用后面的排序号
# 应用场景
- 使用序号函数,我们可以很方便的获取数据排名,那么计算排名的场景我们就可以使用序号函数
- 销量排名
- 成绩排名
- 等等...
- 按照特定条件分类之后,获取每组的最大值
- 我们插入另一条数据
INSERT INTO `score` (`type`, `name`, `score`) VALUES ('高等数学2','test666', 85.00);
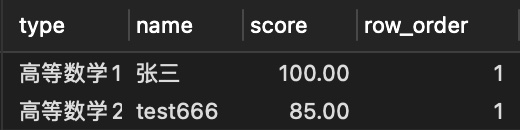
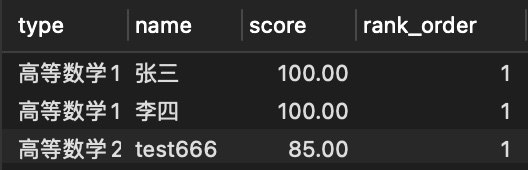
- 获取每个学科成绩最高的一个同学
SELECT
*
FROM
(
SELECT
type,
name,
score,
ROW_NUMBER() OVER ( PARTITION BY type ORDER BY score desc) AS row_order
FROM
score
) AS t
where row_order = 1;
- 获取每个学科成绩最高的同学
SELECT
*
FROM
(
SELECT
type,
name,
score,
RANK() OVER ( PARTITION BY type ORDER BY score desc) AS rank_order
FROM
score
) AS t
where rank_order = 1;
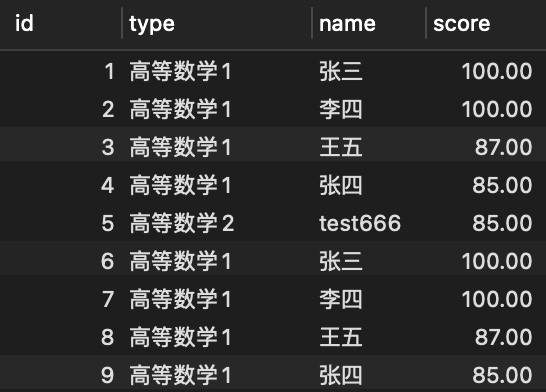
- 清理重复数据
- 我们将之前的数据在插入一次,得到有重复数据的结果集
- 执行sql
DELETE
FROM
score
WHERE
id NOT IN (
SELECT
id
FROM
( SELECT id, ROW_NUMBER() OVER ( PARTITION BY type, name, score ORDER BY score DESC ) AS row_order FROM score ) AS t
WHERE
row_order = 1
);
- 执行结果
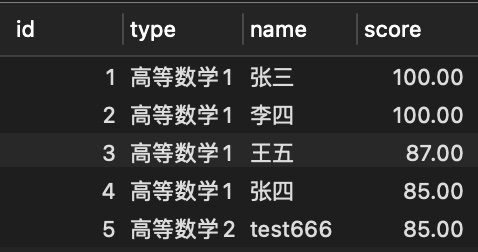
- SQL解析
- 按照学科(type),姓名(name),分数(score)将数据分组,获取每组分数最大值的id
- 将不在id列表中的数据删除
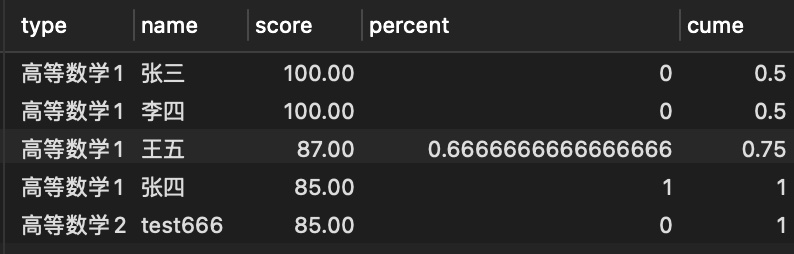
# 分布函数
SELECT
*
FROM
(
SELECT
type,
name,
score,
PERCENT_RANK() OVER ( PARTITION BY type ORDER BY score desc) AS percent,
CUME_DIST() OVER ( PARTITION BY type ORDER BY score desc) AS cume
FROM
score
) AS t;
# 前后函数
- 当n为0的时候,判断当前行数据是否符合条件,0:不符合,1:符合
SELECT
type,
name,
score,
LAG(score > 90,0) OVER ( PARTITION BY type ORDER BY score desc) ,
LEAD(score > 90,0) OVER ( PARTITION BY type ORDER BY score desc)
FROM
score

- 当n不等于0的时候,根据rank排序后,判断(前/后)第n行的数据是否符合条件,0:不符合,1:符合
# 头尾函数
# FIRST_VALUE(expr)
FIRST_VALUE()的结果容易理解,直接在分组结果的所有行记录中输出同一个满足条件的首个记录
# 应用场景
- 获取行数组,并给每条数据设置组内的分数最大值
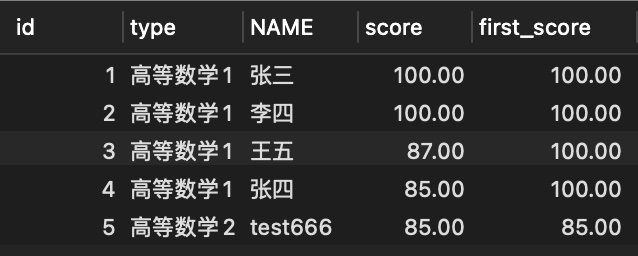
SELECT
id,
type,
NAME,
score,
FIRST_VALUE( score ) OVER ( PARTITION BY type ORDER BY score DESC ) first_score
FROM
score;
# LAST_VALUE(expr)
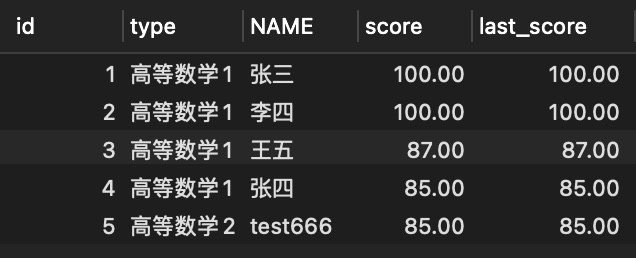
LAST_VALUE()默认统计范围是 rows between unbounded preceding and current row,也就是取当前行数据与当前行之前的数据的比较。
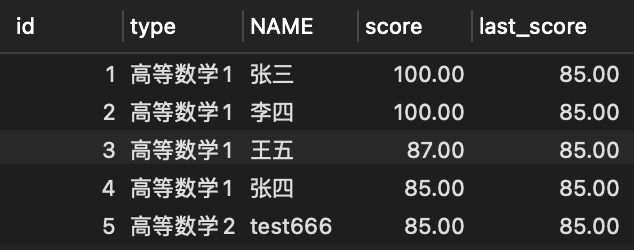
那么如果我们直接在每行数据中显示最后的那个数据,需在order by 条件的后面加上语句:rows between unbounded preceding and unbounded following , 也就是前面无界和后面无界之间的行比较。
# 默认统计范围,与在order by后加排序语句的比较
- 不加
SELECT
id,
type,
NAME,
score,
LAST_VALUE( score ) OVER ( PARTITION BY type ORDER BY score DESC ) last_score
FROM
score;
- 加
SELECT
id,
type,
NAME,
score,
LAST_VALUE( score ) OVER ( PARTITION BY type ORDER BY score DESC rows BETWEEN unbounded preceding AND unbounded following ) last_score
FROM
score;
可以比较明显的看出,默认的查询只显示了当前行的查询结果,而加上之后,last_score填充的是分组的分数最小值
# 其他函数
# NTH_VALUE(expr,n)
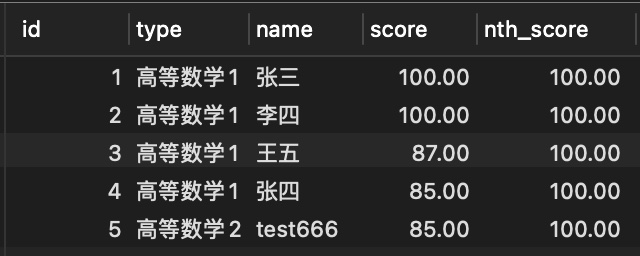
NTH_VALUE(expr, n)中的第二个参数是指这个函数取排名(根据指定字段排序后的自然排序)第几的记录,返回窗口中第n个expr的值。expr可以是表达式,也可以是列名。
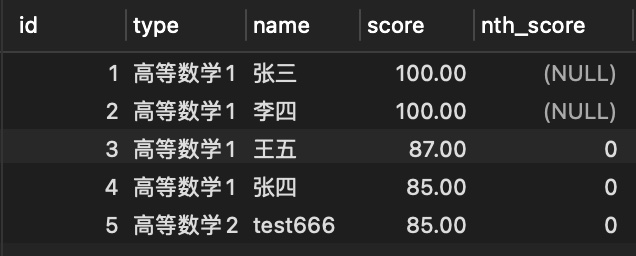
- 取排名第一的分数
SELECT
id,
type,
name,
score,
NTH_VALUE( score, 1 ) OVER ( ORDER BY score desc ) nth_score
FROM
score;
- 排名第三的用户,分数是否大于90
SELECT
id,
type,
name,
score,
NTH_VALUE( score > 90, 3 ) OVER ( ORDER BY score desc ) nth_score
FROM
score;
# NTILE(n)
将分区中的有序数据分为n个等级,记录等级数
# 应用场景
NTILE(n)函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到n个并行的进程分别计算,此时就可以用NTILE(n)对数据进行分组(由于记录数不一定被n整除,所以数据不一定完全平均),然后将不同桶号的数据再分配。
比较简单的来说,就是将用户分组
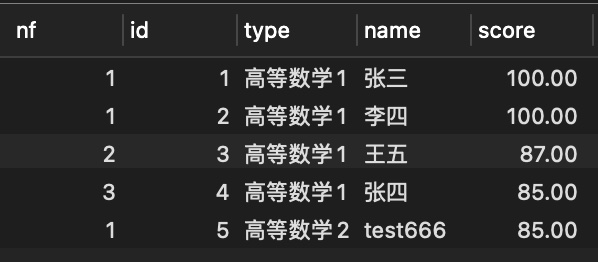
- 将按type分组的用户在按分数分成3组
SELECT
NTILE(3) OVER w AS nf,
id, type,name, score
FROM score tcs
WINDOW w AS (PARTITION BY type ORDER BY score desc);