# 为什么使用了策略on duplicate key update也会报唯一键冲突
# 前言
今天遇到了一个问题,同事问我,为什么她使用了策略on duplicate key update,在跑任务的时候,生产环境居然报错唯一索引重复,无法插入数据。那么要解决这个问题,我们需要对这个策略有充分的了解。
遇到问题的语句如下:
INSERT INTO `table` ( `id`, `field1`, `field2`, `field3`)
VALUES
( 1, 'xxx', 'xxx', 'xxx' )
on duplicate key update
id = 1, `field1`= 'xxx', field2 = 'xxx', field3 = 'xxx'
# 机制
# 触发时机
官方解答
If you specify an ON DUPLICATE KEY UPDATE clause and a row to be inserted would cause a duplicate value in a UNIQUE index or PRIMARY KEY, an UPDATE of the old row occurs.
译文
如果指定ON DUPLICATE KEY UPDATE语句,那么当将要插入的行导致Unique index(唯一索引)或Primary key(主键索引)值重复的时候,就会发生旧数据的更新。
通过这个我们可以明确,on duplicate key update在唯一索引或者主键索引冲突后就会触发更新操作。
# 优先级
我们很容易想到一个问题,既然是唯一索引或者主键索引冲突后触发,那么当待插入的数据与一条数据的唯一索引冲突,与另一条数据的主键索引冲突,会怎么更新呢?
在插入一行数据时,会验证这行数据和现有主键,唯一键是否存在冲突。验证的过程中,每个键的被验证的优先级是不同的,在使用某个键验证时,检查到存在某行数据和待插入数据存在冲突时,那么就更新被检查的这行数据。剩余的其他键,不会再被验证。所以这里被更新的数据行,和检验冲突时被检验的键的优先级定义有很大关系。
在MySQL中,主键的优先级最高,其他各个唯一键的优先级,取决于创建表的时候,唯一键定义的先后顺序,顺序靠前的,被优先验证,顺序靠后的唯一键,被验证的优先级也就比较低。
通过这个我们可以得出结论:使用断路原则进行验证,主键 > 唯一键(多个唯一键按创建时间的先后顺序,优先级由高到低)
# 问题复现
通过上面的讨论,我们可以大概猜想,极有可能就是因为插入的数据与一条数据的唯一索引冲突,与另一条数据的主键索引冲突导致了本次的问题,话不多说,开始验证~
# 建表
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) DEFAULT NULL COMMENT '姓名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱',
`create_time` datetime DEFAULT NULL,
`tes` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `uk_name_idx` (`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
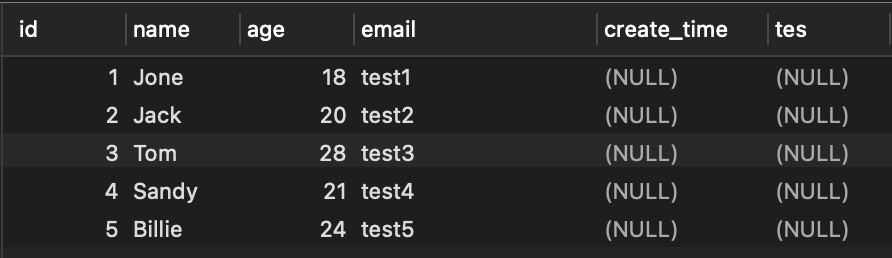
# 插入几条数据
INSERT INTO `user` (`id`, `name`, `age`, `email`, `create_time`, `tes`) VALUES (1, 'Jone', 18, 'test1', NULL, NULL);
INSERT INTO `user` (`id`, `name`, `age`, `email`, `create_time`, `tes`) VALUES (2, 'Jack', 20, 'test2', NULL, NULL);
INSERT INTO `user` (`id`, `name`, `age`, `email`, `create_time`, `tes`) VALUES (3, 'Tom', 28, 'test3', NULL, NULL);
INSERT INTO `user` (`id`, `name`, `age`, `email`, `create_time`, `tes`) VALUES (4, 'Sandy', 21, 'test4', NULL, NULL);
INSERT INTO `user` (`id`, `name`, `age`, `email`, `create_time`, `tes`) VALUES (5, 'Billie', 24, 'test5', NULL, NULL);
# 准备结果
# 准备sql
准备一条sql,id与第一条数据冲突,name与第5条sql冲突
INSERT INTO `user` ( `id`, `name`)
VALUES
( 1, 'Billie')
on duplicate key update
id = 1, `name`= 'Billie'
# 执行结果
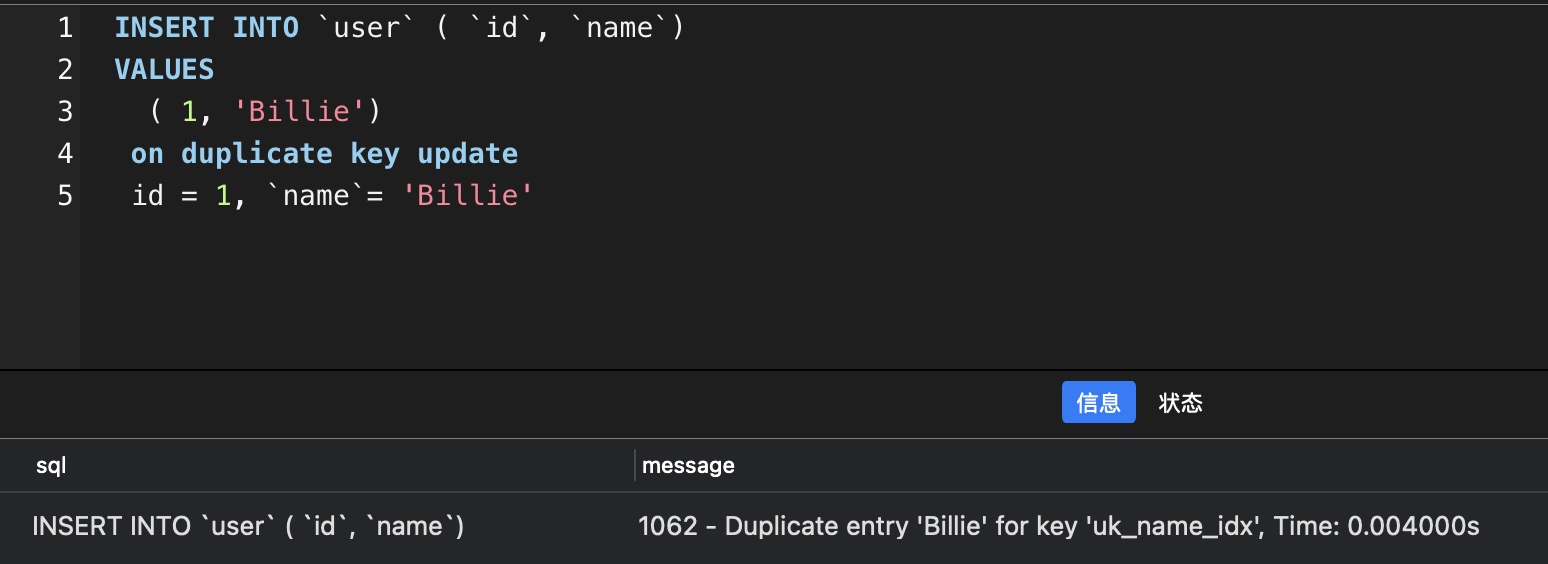 果然,问题复现了。就算是有冲突更新策略,在数据异常的情况下,也还是会报错。
果然,问题复现了。就算是有冲突更新策略,在数据异常的情况下,也还是会报错。
# 结论
如果要使用冲突策略on duplicate key update,需要让结果在自己的控制范围内。人为先行确定到底是根据主键更新还是根据唯一键更新,选个一个即可,避免因为数据异常出现问题,中断流程。