# 云原生大数据计算服务 MaxCompute
云原生大数据计算服务(MaxCompute)是一种快速、完全托管的TB/PB级数据仓库解决方案。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
MaxCompute是适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,以Serverless架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,可以经济并高效地分析处理海量数据。
随着数据收集手段不断丰富,行业数据大量积累,数据规模已增长到了传统软件行业无法承载的海量数据(TB、PB、EB)级别。MaxCompute提供离线和流式数据的接入,支持大规模数据计算及查询加速能力,提供面向多种计算场景的数据仓库解决方案及分析建模服务。MaxCompute还提供完善的数据导入方案以及多种经典的分布式计算模型,可以不必关心分布式计算和维护细节,便可轻松完成大数据分析。
MaxCompute适用于100 GB以上规模的存储及计算需求,最大可达EB级别,并且MaxCompute已经在阿里巴巴集团内部得到大规模应用。MaxCompute适用于大型互联网企业的数据仓库和BI分析、网站的日志分析、电子商务网站的交易分析、用户特征和兴趣挖掘等。详细发展历程、产品荣誉及客户案例请参见发展历程和客户案例。
MaxCompute深度融合了:
DataWorks 基于DataWorks实现一站式的数据同步、业务流程设计、数据开发、管理和运维功能。
机器学习PAI 基于机器学习平台的算法组件实现对MaxCompute数据进行模型训练等操作。
Quick BI 基于Quick BI对MaxCompute数据进行报表制作,实现数据可视化分析。
# 学习路径
可以通过MaxCompute学习路径 (opens new window)快速了解MaxCompute的相关概念、基础操作、进阶操作等。
# 核心功能
| 功能分类 | 功能描述 |
|---|---|
| 全托管的Serverless在线服务 | 对外以API方式访问的在线服务,开箱即用。 预铺设大规模集群资源,可以按需使用、按量计费。无需平台运维,最小化运维投入。 |
| 弹性能力与扩展性 | 存储和计算独立扩展,支持企业将全部数据资产在一个平台上进行联动分析, 消除数据孤岛。支持实时根据业务峰谷变化分配资源。 |
| 统一丰富的计算和存储能力 | MaxCompute支持多种计算模型和丰富的UDF。采用列压缩存储格式, 通常情况下具备5倍压缩能力,可以大幅节省存储成本。 |
| 与DataWorks深度集成 | 一站式数据开发与治理平台DataWorks,可实现全域数据汇聚、融合加工 和治理。DataWorks支持对MaxCompute项目进行管理以及Web端查询编辑。 |
| 集成AI能力 | 与机器学习平台PAI无缝集成,提供强大的机器学习处理能力。可以使用熟悉 的Spark-ML开展智能分析。使用Python机器学习三方库。 |
| 深度集成Spark引擎 | 内建Apache Spark引擎,提供完整的Spark功能。与MaxCompute计算资源、 数据和权限体系深度集成。 |
| 湖仓一体 | 集成对数据湖(OSS或Hadoop HDFS)的访问分析,支持通过外部表映射、 Spark直接访问方式开展数据湖分析。在一套数据仓库服务和用户接口下, 实现数据湖与数据仓库的关联分析。详细信息,请参见MaxCompute湖仓一体 (opens new window)。 |
| 支持流式采集和近实时分析 | 支持流式数据实时写入并在数据仓库中开展分析。与云上主要流式服务深度集成, 轻松接入各种来源的流式数据。支持高性能秒级弹性并发查询,满足近实时分析场景需求。 |
| 提供持续的SaaS化云上数据保护 | 为云上企业提供基础设施、数据中心、网络、供电、平台安全能力、用户权限管理、 隐私保护等三级超20项安全功能,兼具开源大数据与托管数据库的安全能力。 |
# 产品架构
MaxCompute的产品架构如下。
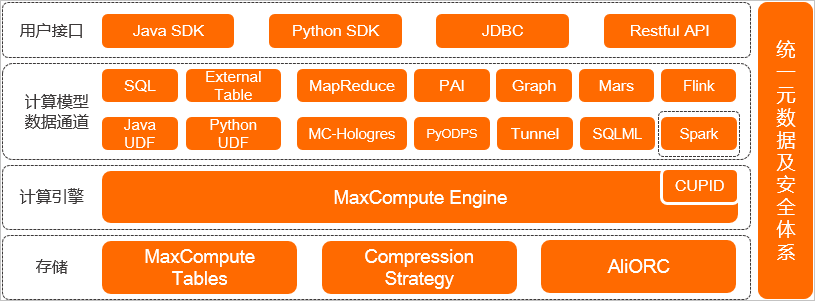
| 模块名称 | 功能说明 |
|---|---|
| 存储 | MaxCompute Tables:表 (opens new window)是MaxCompute的数据存储单元。 MaxCompute中不同类型作业的操作对象(输入、输出)都是表。 Compression Strategy:MaxCompute采用列压缩存储格式,通常情况下具备5倍压缩能力。 AliORC:MaxCompute数据存储格式全面升级为AliORC,具备更高存储性能。 |
| 计算引擎 | MaxCompute本身具备计算引擎能力。 在处理Spark作业时,MaxCompute运行在阿里云自研的CUPID平台之上, 可以原生支持开源社区Yarn所支持的计算框架。 |
| 计算模型数据通道 | MaxCompute支持多种数据通道满足多场景需求: SQL (opens new window):MaxCompute对外提供SQL功能。可以将MaxCompute作为传统的数据库软件操作, 但其却能处理EB级别的海量数据。 说明MaxCompute SQL不支持事务、索引。MaxCompute的SQL语法与Oracle、MySQL有一定差别, 无法将其他数据库中的SQL语句无缝迁移至MaxCompute中。详情请参见与其他SQL语法的差异 (opens new window)。 MaxCompute主要用于100 GB以上规模的数据计算,因此MaxCompute SQL最快支持在分钟或秒钟 级别完成查询返回结果,但无法在毫秒级别返回结果。 MaxCompute SQL的优点是学习成本低,不需要了解复杂的分布式计算概念。如果具备数据库操作经验,便可快速熟悉MaxCompute SQL的使用。 External Table (opens new window):提供处理除MaxCompute内部表以外的其他数据的能力。 可以通过一条简单的DDL语句,在MaxCompute上创建一张外部表,通过外部表关联外部数据源。 Java UDF (opens new window):当MaxCompute的内建函数无法满足计算需求时,可以通过Java构建自定义函数。 Python UDF (opens new window):当MaxCompute的内建函数无法满足计算需求时,可以通过Python构建自定义函数。 MapReduce (opens new window):MapReduce是MaxCompute提供的Java MapReduce编程模型,它可以简化开发流程,更为高效。 Hologres (opens new window):Hologres与MaxCompute在底层无缝连接,无须移动数据,即可使用标准的PostgreSQL 语句查询分析MaxCompute中的海量数据,快速获取查询结果。 PAI (opens new window):PAI是基于MaxCompute的一款机器学习算法平台。它实现了数据无需搬迁,便可进行从 数据处理、模型训练、服务部署到预测的一站式机器学习。 PyODPS (opens new window):PyODPS是MaxCompute的Python版本的SDK,提供简单方便的Python编程接口。 Graph (opens new window):Graph是一套面向迭代的图计算处理框架。 Tunnel (opens new window):提供高并发的数据上传下载服务。 Mars (opens new window):Mars是一个基于张量的统一分布式计算框架。Mars能利用并行和分布式技术,为Python数据科学栈加速。 SQLML (opens new window):SQLML功能依赖MaxCompute和机器学习PAI。可以通过客户端开发MaxCompute SQLML作业,基于机器学习PAI对MaxCompute上的数据进行学习,并利用机器学习模型对数据进行预测,进而为业务规划提供指导。 Flink (opens new window):Flink为MaxCompute提供实时数据处理能力。 Spark (opens new window):Spark是MaxCompute提供的兼容开源Spark的计算服务。它在统一的计算资源和数据集权限体系之上,提供Spark计算框架,支持以熟悉的开发使用方式提交运行Spark作业,满足更丰富的数据处理分析需求。 |
| 用户接口 | MaxCompute提供如下用户接口:Java SDK (opens new window)Python SDK (opens new window)JDBC (opens new window)Restful API |
| 统一元数据及安全体系 | MaxCompute的Information Schema (opens new window)提供项目元数据及使用历史数据等信息, 可以对作业的运行情况,例如资源消耗、运行时长、数据处理量等指标进行分析, 用于优化作业或规划资源容量。MaxCompute还提供了完善的安全管理体系, 例如访问控制、数据加密、动态脱敏等为数据安全性提供保障。 |
# 产品优势
MaxCompute的主要优势如下:
简单易用
- 面向数据仓库实现高性能存储、计算。
- 预集成多种服务,标准SQL开发简单。
- 内建完善的管理和安全能力。
- 免运维,按量付费,不使用不产生费用。
匹配业务发展的弹性扩展能力
存储和计算独立扩展,动态扩缩容,按需弹性扩展,无需提前规划容量,满足突发业务增长。
支持多种分析场景
支持开放数据生态,以统一平台满足数据仓库、BI、近实时分析、数据湖分析、机器学习等多种场景。
开放的平台
- 支持开放接口和生态,为数据、应用迁移、二次开发提供灵活性。
- 支持与Airflow、Tableau等开源和商业产品灵活组合,构建丰富的数据应用。